Sonnet5技术拆解:92.4%背后的自适应推理架构与中档模型逆袭逻辑
去年冬天第一次认真用Sonnet写代码时,心里其实没底。那个凌晨,我把一个三百行的Python脚本丢给它,改完跑了一下午,只修了两三个bug。当时的判断是:能辅助,但离替代人还差得远。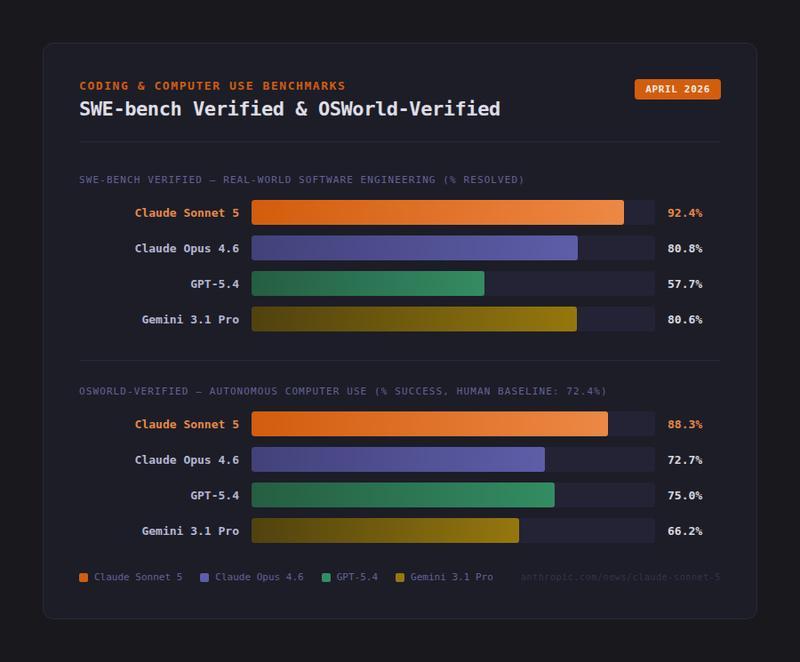
回溯三个月:行业三次变天的节奏
把时间线拉出来看,这波AI模型的迭代节奏异常清晰。2月19日Gemini3.1Pro发布,GPQADiamond登顶,Google精准卡位OpenAI的软肋。3月5日GPT-5.4上线,75%的OSWorld成绩让整个行业喊出「agent时代要来了」。中间夹着一个微妙的事实:Sonnet4.6作为Anthropic的中档型号,已经开始出现「以下犯上」的怪现象——开发者对战中,59%的情况下选了它而非自家旗舰Opus4.5。
这种内部倒挂说明一个核心问题:模型规模不是唯一护城河,推理效率与响应质量正在重新定义评估维度。
关键节点:92.4%的技术含义
Sonnet5的92.4%不是简单的数字跃升。SWE-benchVerified的测试逻辑极度严格:给模型一个从未见过的真实GitHub代码库,附上issue描述,要求它理解问题、定位bug、写出修复、通过测试。没有训练数据可背,没有套路可套,完全模拟生产场景。
对比几个关键节点:Opus4.6是80.8%,Gemini3.1Pro是80.6%,GPT-5.4是57.7%。Sonnet5的92.4%意味着,十次任务中能成功九次半。这个可靠性水平,已经触及CI/CD流程集成的门槛。
方法提炼:自适应思考架构的工作原理
Sonnet5没有靠堆参数规模取胜。它的核心突破在于「自适应思考架构」——动态分配推理深度,碰到简单问题时快速响应,碰到复杂问题时自动激活深层推理链。这种策略在技术层面叫「该省省该花花」,在商业层面叫「精准算力投放」。
另一个硬指标:2Mtoken上下文窗口正式脱离beta状态。长文档处理、遗留代码库理解、多轮对话的瓶颈一次性打通。对比之前128K上下文时代的频繁截断,这是一个质的飞跃。
应用指导:中档模型的选型逻辑
回到价格维度。API定价$3/$15每百万token,和Sonnet4.6完全一致。这意味着花五分之一Opus4.6的价格,可以买到更强的实际表现。开发者的选择题很简单:花3块钱买更强的,还是花15块钱买更弱的?
选型建议:现有业务流依赖代码生成的,直接切换;还在用Opus4.6做主力模型的,测一轮ROI再做决定;agent化改造的,Sonnet5是当前最优的控制器候选。92.4%的数字背后,不只是性能领先,是一种新的开发范式正在成型。
